October 06, 2025
“Just pull the data from Benchling.”
If only it were that simple.
You’re also pulling from three different sequencing platforms, two legacy Excel trackers someone maintains “just in case,” and a PostgreSQL database with a schema that was designed before anyone on the current team started.
Each source has different naming conventions. Different update frequencies. Different levels of trust. And somehow, you need to combine all of this into something your scientists can actually use.
This is where I’ve found the medallion architecture invaluable.
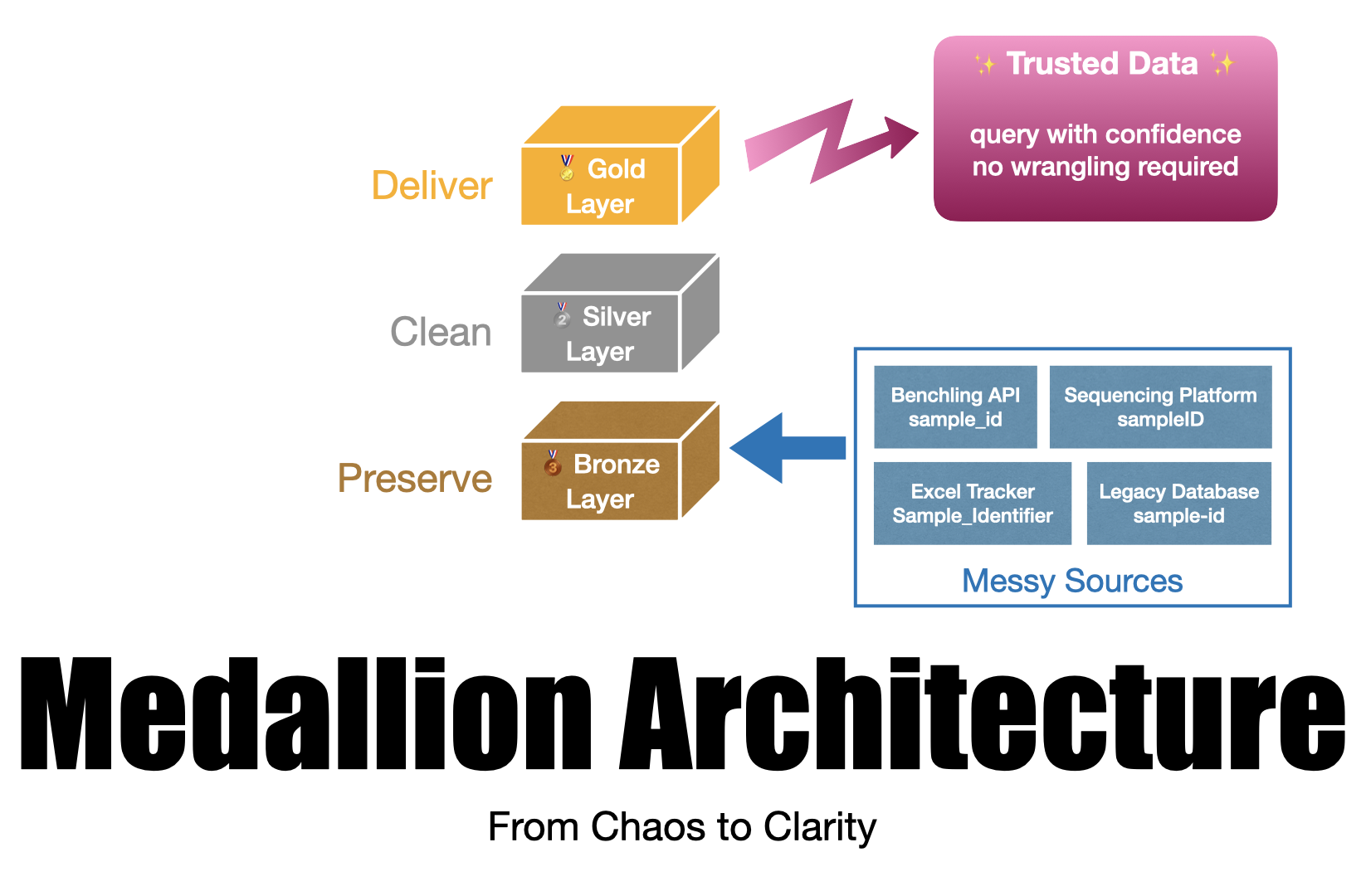
𝗪𝗵𝗮𝘁 𝗶𝘀 𝘁𝗵𝗲 𝗺𝗲𝗱𝗮𝗹𝗹𝗶𝗼𝗻 𝗮𝗿𝗰𝗵𝗶𝘁𝗲𝗰𝘁𝘂𝗿𝗲?
It’s a systematic way to transform messy, multi-source data into something trustworthy and useful. Think of it as three progressive layers of refinement:
🥉 𝗕𝗿𝗼𝗻𝘇𝗲 𝗟𝗮𝘆𝗲𝗿: Raw data, exactly as it arrives
→ One table per source, no transformations → Your source of truth for “what did we actually receive?” → Preserves everything, even the weird edge cases
🥈 𝗦𝗶𝗹𝘃𝗲𝗿 𝗟𝗮𝘆𝗲𝗿: Cleaned and standardized data
→ Consistent naming conventions across all sources → Data quality checks and validation rules applied → Schema harmonization (finally, all your sample IDs match!) → This is where you fix the “sample_id” vs “sampleID” vs “Sample_Identifier” problem
🥇 𝗚𝗼𝗹𝗱 𝗟𝗮𝘆𝗲𝗿: Business-ready data
→ Domain-specific logic applied
→ Aggregations and calculations complete
→ Ready for scientists to query directly
→ This is what powers your dashboards and tools
𝗪𝗵𝘆 𝘁𝗵𝗶𝘀 𝗺𝗮𝘁𝘁𝗲𝗿𝘀
When you serve data from the gold layer, your users don’t need to know that their simple query is actually reconciling data from five different sources. They don’t need to remember which system uses underscores and which uses camel case. They just get the answer they need.
And when something breaks upstream? You can trace it back through the layers without touching production data.
The bronze layer lets you say “here’s exactly what we received” when debugging. The silver layer ensures consistency. The gold layer delivers value.
𝗧𝗵𝗲 𝗽𝗿𝗮𝗰𝘁𝗶𝗰𝗮𝗹 𝗶𝗺𝗽𝗮𝗰𝘁
This architecture transformed how we handled data integration at Korro. Instead of constantly troubleshooting why two datasets didn’t align, we had clear stages where we could pinpoint exactly where problems originated.
More importantly, it meant scientists could trust the data they were seeing. When everything is standardized in gold, they can focus on the science instead of data wrangling.
For those of you managing multiple data sources: How are you handling schema mismatches and data reconciliation? Are you building transformations on the fly, or do you have a structured approach?

