November 13, 2025
Data Pipelines That Scientists Can Debug (Without Calling You at 9 PM)
“Hey, the pipeline failed again. Can you take a look?”
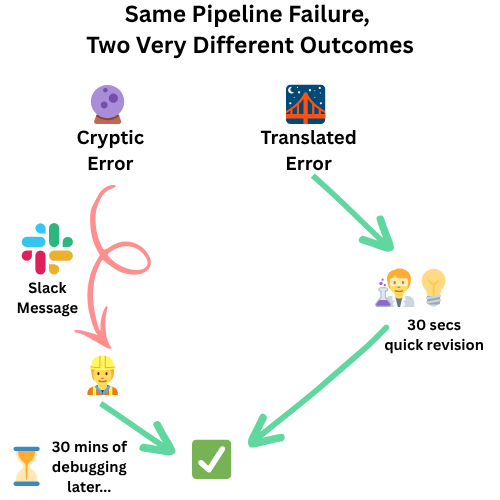
This Slack message means your next hour is gone. You’ll dig through logs, decipher SQL errors, and eventually discover something simple: a sample ID mismatch, a missing metadata field, or a file in the wrong format.
The scientist could have fixed it in 30 seconds—if the error message had told them what to look for.
I’ve watched brilliant researchers stare at “Foreign key constraint violation in table seq_metadata” for 10 minutes before asking for help. The pipeline was doing its job—catching bad data before it corrupted the database. But the error message was useless.
The underlying problem was pretty straightforward: sample IDs in the sequencing file didn’t match our experiment registry. A 30-second fix for someone who knows where to look. An unsolvable mystery for everyone else.
Good data engineering includes translating technical failures into actionable scientific context.
Here’s what I now build into every production pipeline:
- Error messages that say what AND why: “Sample ID ABC123 not found in experiment registry. Check Benchling or contact data team if this sample should exist.”
- Data quality checks in scientific terms: “Missing replicate numbers for 3 samples in plate P2024-089. Replicates required for statistical analysis.”
- Logging that tells a story: Timestamps, input files, sample counts, quality metrics so scientists can reconstruct what happened.
- Retry logic that makes sense for biology: Retry network glitches. Don’t retry failed QC—that needs human judgment.
- Clear next steps in failures: Point to docs, suggest who to contact, or indicate if this is expected.
The goal isn’t eliminating errors—it’s making them interpretable.
When a scientist sees “QC failed: 12% of reads below threshold (expected <5%). Contact sequencing core,” they know what to do. “ValueError: invalid literal for int()” leaves them stuck.
The best pipeline is one that makes both teams successful.
Data engineers get fewer interruptions and better bug reports. Scientists get independence and faster resolution. Everyone wins when failures are observable and actionable.
Since implementing these patterns, debugging interruptions dropped significantly. Not because pipelines stopped failing—they still do. But now when they fail, the error message points scientists directly to the problem. Which pattern would have the biggest impact for your team? 🧬💻

